Routinely
In Progress
This is a website built in Angular and Go. It was a group effort between classmates and I for our Intro to Software Engineering Class.
Routinely is a calendar website that will (eventually) automatically schedule your events for you as you put them in. To accomplish this, we used typescript, angular, and clarity.design on the frontend, and go on the backend. It is a semester long project, and will be finished soon. When it's finished I plan on making it it's own github page so that people all over the world can use it if they so please.
Cache Simulation
Completed on Dec 15th, 2022
I wrote this in Python, and it was very empowering to see how strong Python is right out of the box.
For this project, we had to write 3 different types of cache simulators, that simulated direct mapped, set associative (n-way), and fully associative caches. We had to implement a way to adjust cache size and set associativity, as well as map the performance of the three different caches onto a graph representing speed vs size. For this project, I used nvim and the command line. I used this time to start to get used to vim keybinds.
Nhovas
Completed on Dec 6th, 2022
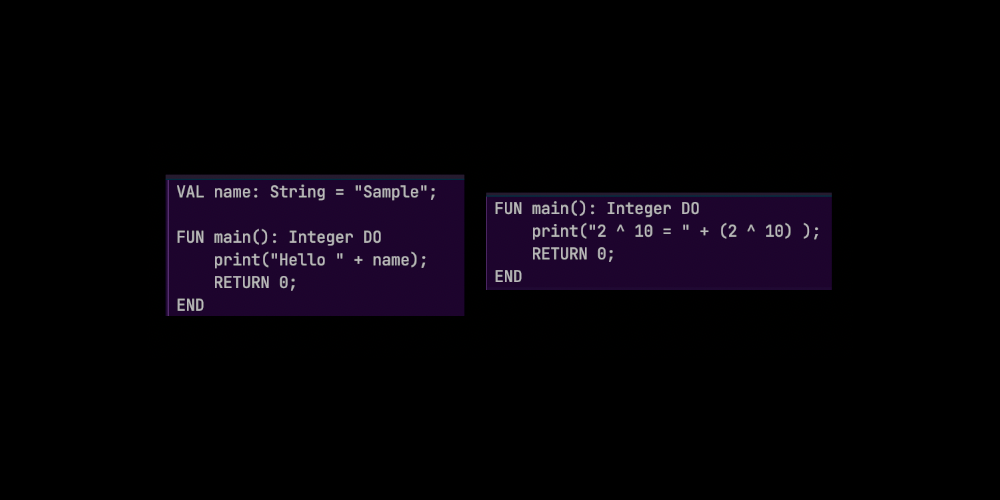
Image of functional Nhovas code.
Nhovas is the name of the language that I programmed in my Introduction to Programming Languages class. We had to write a Lexer, Parser, Analyzer, Interpreter, and Generator, all inside of Java. This was an intense, semester long project that taught me a lot. For this project, I used IntelliJ Idea, and data structures provided by my professor.
Terpscraper
Completed on Oct 7th, 2022
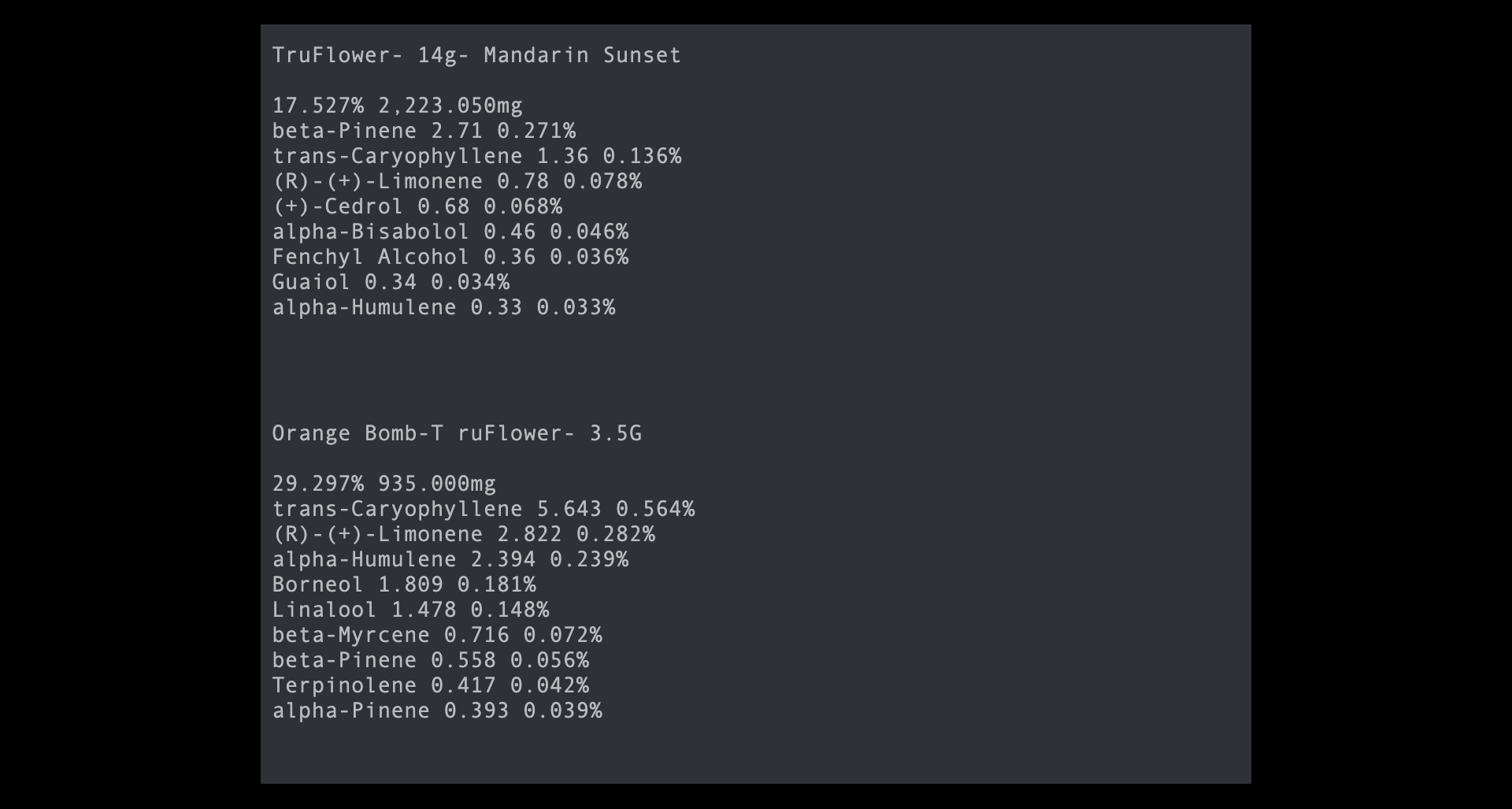
Image of Terpscraper output.
This was a side project that was not school-related. I have a medical cannabis card, and the dispensaries make it difficult to actually know what you're getting when you buy it, so I decided to build my Python skills by creating a solution for that. I used Trulieve's website, as it doesn't have an API. I used BeautifulSoup 4 to webscrape the site, get all of the product urls, then scrape the product sites for a link to a pdf with the test results. I then used PyPDF2 to parse through these PDF files and extract THC and terpene percentages. I then collected all of these results and put them into a cleaned up text file. It has been used by myself and a few other people in the state with medical cards.
About Me

I am a software developer that is currently based out of Gainesville, Florida. I am in my junior year of my Computer Science degree, on track to graduate in four years. I am well versed in C++ and Java, and am teaching myself Python, Swift, and HTML/CSS/JS.